
Compared to CPUs which latency-oriented architectures, GPUs mainly focus on overall throughput. The high GPUs throughput is achieved through concurrent execution of massive number of concurrent threads sharing identical kernel code. High throughput is achieved by hiding memory access latency across parallel threads. While some threads are waiting for their data or instructions, others can execute. To hide memory access latency, GPUs have dedicated hardware schedulers performing scheduling decisions at warp-level granularity. A warp (also called wavefront in OpenCL) is a group of threads sharing same Program Counter (PC) and executing in lock-step mode.
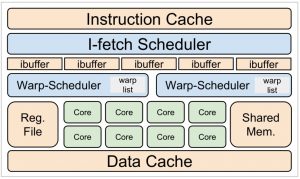
With trend toward using GPUs for a diverse range of applications (e.g. vision and scientific computing) new challenges have been raised. One of the main challenges is inter-warp conflicts in the shared resources including I$, D$ and compute unites. The conflicts in the shared resources mainly caused by inter-warp divergence which is uneven execution progress across the concurrent warps. Excessive inter-warp divergence may hinder GPUs to achieve their peak throughput. This motivates the need for approaches that manage inter-warp divergence, avoiding I$ conflicts, for divergence-sensitive benchmarks.
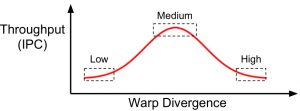
The work is based on our newly introduced concept: Warp Progression Similarity (WPS) which quantifies the temporal execution similarity of concurrent warps. We anticipate a conceptual trade-off between inter-warp divergence and IPC for the divergence-sensitive benchmarks with high inter-warp conflicts in I$. While both extremes hinder GPUs to achieve their peak IPC, we anticipate that maximum IPC is achieved with a medium inter-warp divergence. The aim of this project is to employ system-level design principles to manage the inter-warps conflicts in the GPU shared resources including I$ and D$.




